UC-2.2 — Ranking of Samples by Chemical Diversity¶
Module: 2 – Exploratory Analysis: Ranking the Functional Potential of Samples and Compounds
Visualization type: Bar chart (ranking by unique compound diversity per sample)
Primary inputs: BioRemPP results table with sample and compoundname columns
Primary outputs: Ranked list of samples by unique compound count ("chemical diversity")
Scientific Question and Rationale¶
Question: Which biological samples are co-annotated with the widest variety of unique chemical compounds?
This use case ranks each biological sample according to the total number of unique compounds with which it is co-annotated in the dataset. The resulting bar chart provides a comparative view of compound association breadth across biological sources, based on annotation data. By focusing on the count of distinct compound co-annotations, this visualization can highlight which samples have the broadest compound annotation coverage in the dataset.
Data and Inputs¶
- Primary data source:
BioRemPP_Results.xlsx or BioRemPP_Results.csv - Key columns:
sample– identifier for each biological samplecompoundname– name of the chemical compound associated with that sample- Accepted format: semicolon-delimited text table (
.txtor.csv) - Entity of interest: unique compound names associated with each sample
Analytical Workflow¶
-
Data Loading
The primary results table (BioRemPP_Results.xlsx or BioRemPP_Results.csv) is loaded from its semicolon-delimited format. -
Filtering
The dataset is filtered to retain only complete entries containing both a validsampleand acompoundname. Rows missing either field are discarded. -
Aggregation
The filtered data is grouped by each uniquesample. Within each group, the number of distinct compound names is computed (e.g., usingnunique()), yielding a per-sample measure of chemical diversity. -
Sorting and Rendering
The aggregated results are sorted (typically in descending order of unique compound count) and rendered as a bar chart: - one axis represents Samples,
- the other axis represents the count of unique compounds, and
- bar length/height is proportional to the unique compound count for each sample.
How to Read the Plot¶
-
Sample Axis
One axis (X or Y, depending on orientation) lists the individual Samples, each represented by a single bar. -
Compound Count Axis
The other axis represents the absolute count of unique compounds (compoundname) associated with each sample. -
Bar Size and Labels
The bar length (for a horizontal chart) or height (for a vertical chart), together with optional numeric labels, explicitly indicates the total unique compound count for that sample. Taller/longer bars correspond to higher chemical diversity.
Representative Output¶
The image below illustrates a representative output generated by this use case using the example dataset.
Click on the image to enlarge and explore details.
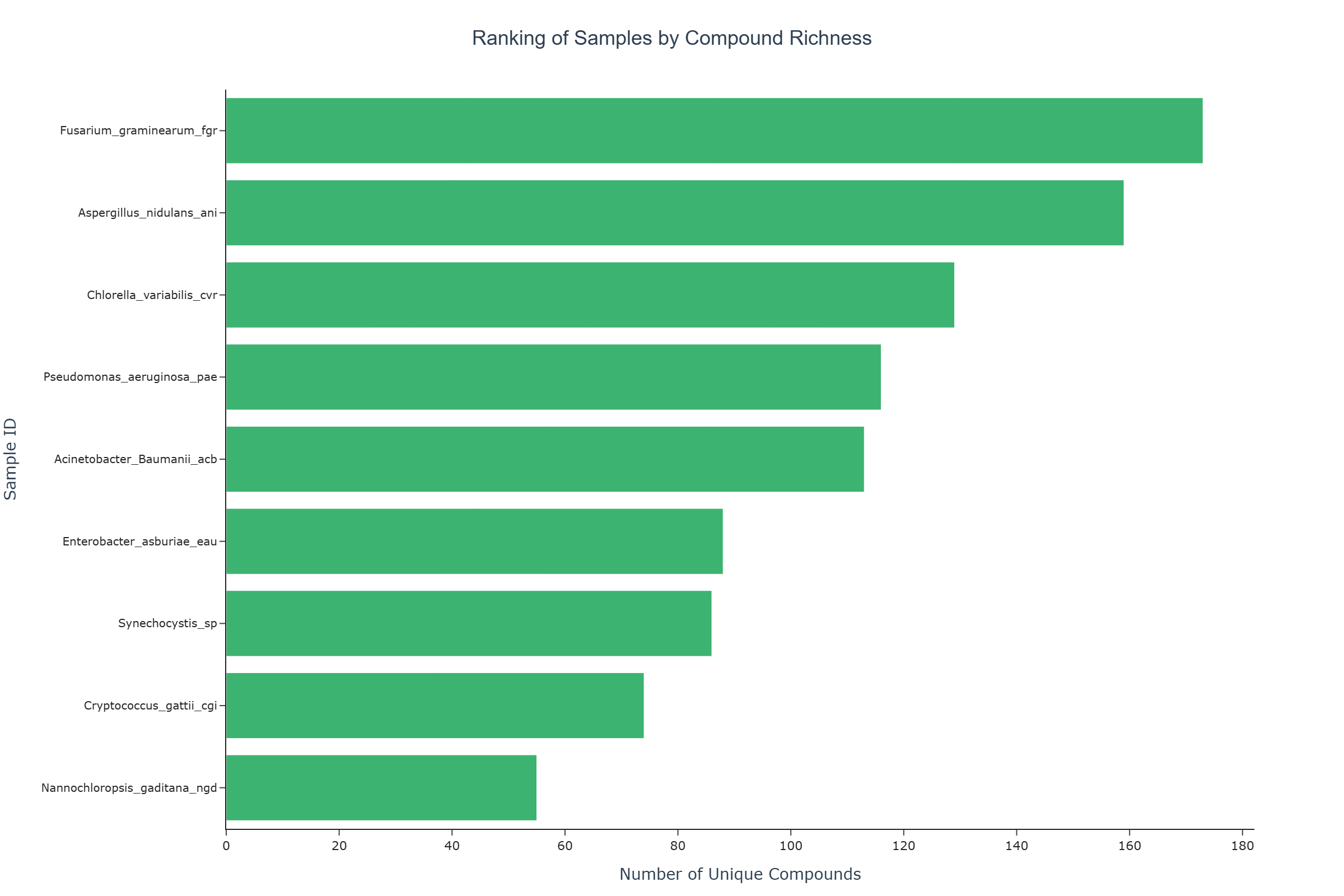
Interpretation and Key Messages¶
-
Compound Association Breadth Samples with taller/longer bars are co-annotated with a greater number of unique compounds in the dataset. This reflects the breadth of annotation-level compound associations and may serve as a basis for comparing samples, but does not confirm actual interaction capacity or metabolic versatility.
-
Comparative Ranking The chart provides a straightforward ranking of samples by compound association count, which can help orient exploratory analyses and hypothesis generation about which samples show broader or narrower compound annotation coverage.
-
Narrow Association Profiles Samples with shorter bars are co-annotated with fewer unique compounds in the dataset. This may reflect a more focused annotation profile, smaller dataset representation, or a narrower compound scope — not necessarily lower biological activity or relevance.
Reproducibility and Assumptions¶
-
Input Format
The analysis assumes a semicolon-delimited table containing at least the columnssampleandcompoundname. -
Uniqueness Definition Compound association count is defined as the count of unique compounds per sample. Multiple occurrences of the same
compoundnamefor a given sample (e.g., across different reactions or genes) are counted only once. -
Scope of Interpretation
The interpretation is directly dependent on the compounds present inBioRemPP_Results.xlsx or BioRemPP_Results.csv. Samples may appear less diverse simply because certain compound classes or environmental conditions are not represented in the underlying dataset.
Activity diagram of the use case¶
Click on the image to enlarge and explore details.
