UC-3.2 — Principal Component Analysis of Samples by Chemical Profile¶
Module: 3 – System Structure: Clustering, Similarity, and Co-occurrence
Visualization type: PCA scatter plot (samples in compound-interaction space)
Primary inputs: BioRemPP results table with sample and cpd (compound) columns
Primary outputs: Sample coordinates on principal components (PC1, PC2) based on chemical interaction profiles
Scientific Question and Rationale¶
Question: How do the samples cluster or separate based on their compound co-annotation profiles (the compounds they are co-annotated with), and which samples have the most similar or distinct compound annotation patterns?
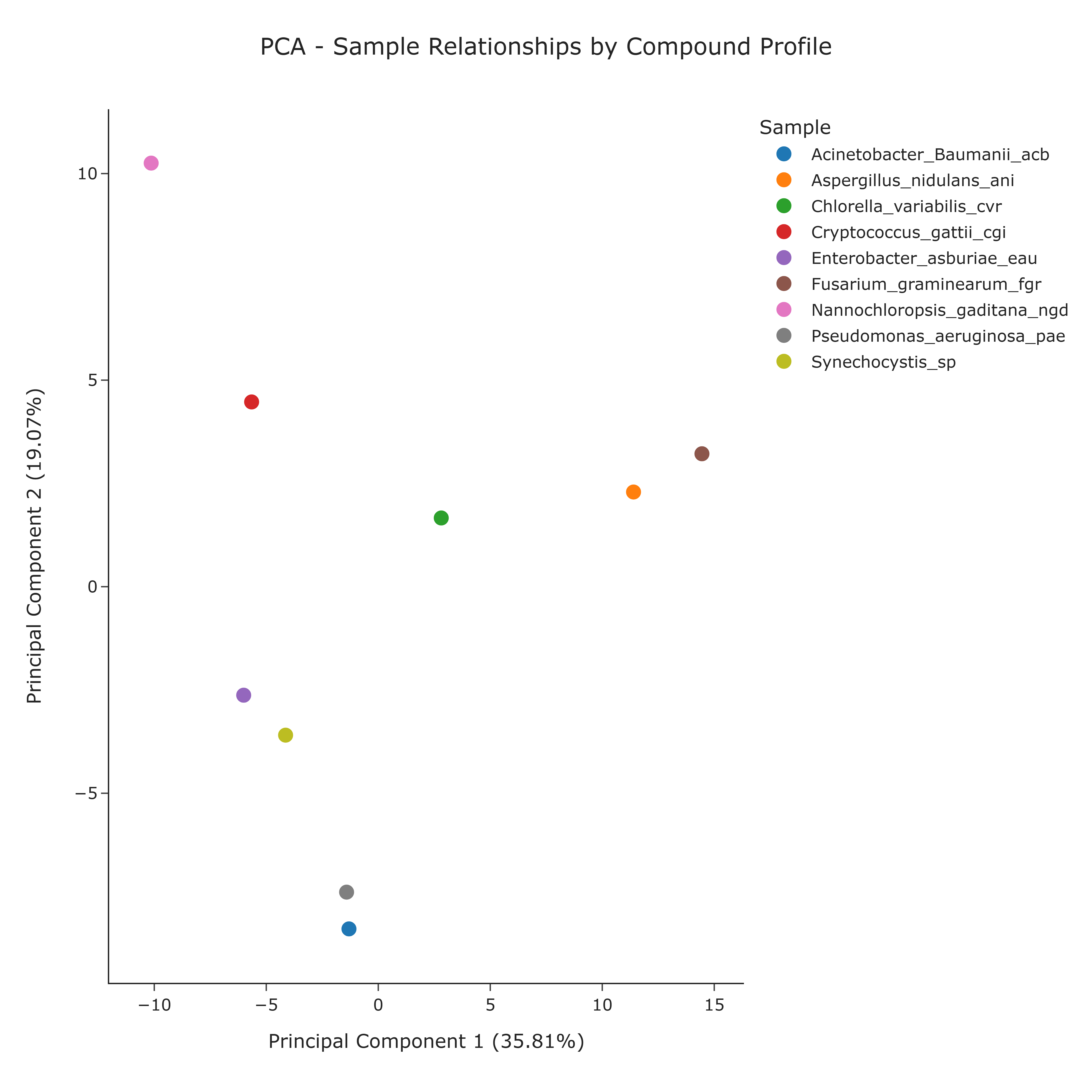
This use case applies Principal Component Analysis (PCA) to characterize relationships among biological samples based on their compound co-annotation profiles rather than their KO annotation repertoires. Each sample is represented by the set of compounds (cpd) with which it is co-annotated in the database. PCA projects these high-dimensional compound presence/absence patterns into a two-dimensional space defined by the first two principal components. This can provide an interpretable map of compound annotation similarity, potentially revealing groups of samples with similar compound co-annotation patterns, as well as samples with unique compound annotation profiles.
Data and Inputs¶
- Primary data source:
BioRemPP_Results.xlsx or BioRemPP_Results.csv - Key columns:
sample– identifier for each biological samplecpd– identifier or name of the chemical compound associated with that sample- Accepted format: semicolon-delimited text table (
.txtor.csv) - Derived structure: binary presence/absence matrix with:
- rows = samples
- columns = unique compounds (
cpd) - cell =
1if the sample is associated with the compound,0otherwise
Analytical Workflow¶
-
Data Loading
The primary results table (BioRemPP_Results.xlsx or BioRemPP_Results.csv) is loaded into memory. -
Matrix Construction
A binary presence/absence matrix is constructed where: - rows correspond to Samples,
- columns correspond to unique compounds (
cpd), and -
each cell is set to
1if the sample is associated with that compound and0otherwise.
This converts the categorical compound interaction data into a numerical format suitable for PCA. -
Data Scaling
The binary matrix is standardized using aStandardScaler(mean-centering and scaling to unit variance). This ensures that all compound features contribute comparably to the PCA, regardless of overall frequency. -
PCA Computation
PCA is applied to the scaled matrix to reduce dimensionality. The first two principal components (PC1 and PC2), which explain the largest fractions of variance in the compound interaction space, are retained for visualization. -
Rendering
The samples are plotted as a scatter plot in the PC1–PC2 plane: - each point represents a Sample, and
- its coordinates correspond to the sample's scores on PC1 (X-axis) and PC2 (Y-axis).
How to Read the Plot¶
-
Points (Samples)
Each point in the scatter plot represents an individual Sample. -
Axes (Principal Components)
- The X-axis corresponds to Principal Component 1 (PC1).
-
The Y-axis corresponds to Principal Component 2 (PC2).
Axis labels typically include the percentage of total variance explained by each component (e.g., "PC1 (28% variance)"). -
Proximity and Distance The distance between points may reflect similarity in compound co-annotation profiles:
- samples that lie close together may be co-annotated with a more similar set of compounds,
- samples that are far apart may differ strongly in the compounds that load heavily on PC1 and/or PC2.
Representative Output¶
The image below illustrates a representative output generated by this use case using the example dataset.
Click on the image to enlarge and explore details.
Interpretation and Key Messages¶
-
Compound Co-annotation Clusters Groups of points that cluster together may indicate sets of samples with similar compound co-annotation profiles across the compound space. These groups may represent samples that share overlapping compound co-annotations and could be worth investigating together.
-
Compound Annotation Divergence and Axes of Variation Separation of samples or clusters along PC1 or PC2 may indicate the main directions of compound annotation divergence in the dataset:
- separation along PC1 may reflect differences driven by compounds with high loadings on PC1,
-
separation along PC2 may reflect analogous patterns for compounds with high loadings on PC2.
-
Annotation Outliers Samples positioned far from the main cluster(s) may possess unique or rare compound co-annotation profiles. These could represent samples with narrowly focused or unusually broad compound annotation patterns and may warrant further investigation.
Reproducibility and Assumptions¶
-
Input Format
The analysis assumes a semicolon-delimited table containing at least the columnssampleandcpd. -
Binary Representation
Each(sample, cpd)combination is treated as a presence/absence event. Multiple occurrences of the same compound for a sample (e.g., via different genes or pathways) are collapsed into a single presence (1). -
Standardization
The PCA is performed on a standardized version of the presence/absence matrix (mean-centered and scaled to unit variance), which is standard practice to prevent features with higher prevalence from dominating the analysis. -
Variance-Based Interpretation
PCA captures linear combinations of compounds that explain variance in the data. It does not explicitly model nonlinear relationships or interaction effects between compounds, which may be explored using complementary methods in other use cases.
Activity diagram of the use case¶
Click on the image to enlarge and explore details.
