UC-5.2 — Sample Similarity (Based on Chemical Profiles)¶
Module: 5 – Modeling Interactions of Samples, Genes, and Compounds
Visualization type: Chord diagram (sample–sample similarity based on shared compounds)
Primary inputs: BioRemPP results table with sample and compoundname columns
Primary outputs: Pairwise similarity matrix of samples based on shared unique compounds
Scientific Question and Rationale¶
Question: How similar are the samples to one another in their compound co-annotation profiles, and what is the structure of these annotation-based sample groups?
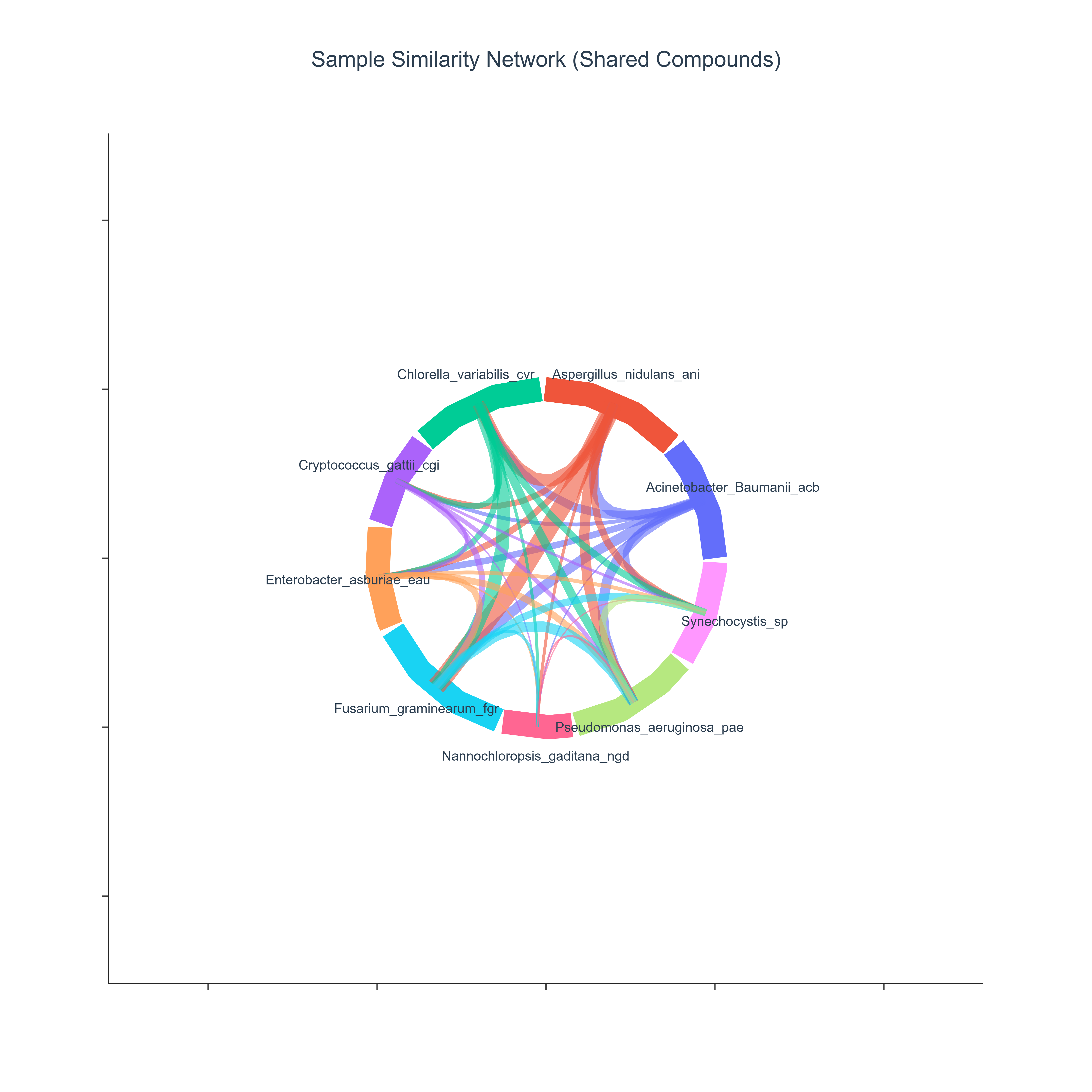
This use case quantifies pairwise compound co-annotation similarity between biological samples by counting how many unique compounds they have in common in the database. The similarities are then represented as a sample–sample chord diagram, in which chord thickness reflects the number of shared compound co-annotations. This can provide an intuitive, network-like view of annotation-based sample groups: clusters of samples that share overlapping compound co-annotations and may warrant joint investigation.
Data and Inputs¶
- Primary data source:
BioRemPP_Results.xlsx or BioRemPP_Results.csv - Key columns:
sample– identifier for each biological samplecompoundname– name (or identifier) of the chemical compound associated with that sample- Accepted format: semicolon-delimited text table (
.txtor.csv) - Derived structures:
- a mapping from each sample to its set of unique compounds
- a pairwise similarity table where each entry is the count of shared compounds between two samples
Analytical Workflow¶
-
Data Loading
The primary results table (BioRemPP_Results.xlsx or BioRemPP_Results.csv) is loaded from its semicolon-delimited format. -
Feature Engineering and Mapping
For each uniquesample, a compound set is constructed: - all unique
compoundnameentries associated with that sample are collected into a set, -
this set represents the sample's compound co-annotation profile.
-
Similarity Calculation
All unique pairs of samples are considered. For each pair: - the intersection of their compound sets is computed,
-
the similarity score is defined as the count of shared unique compound names in this intersection.
-
Link Construction
A table of sample–sample links is built where: - source = sample A,
- target = sample B,
-
value = similarity score (number of shared compounds).
Only pairs with a non-zero similarity may be retained for visualization to reduce clutter. -
Rendering
The similarity data is rendered as a chord diagram: - each sample is represented as an arc on the circle,
- chords (ribbons) connect pairs of samples,
- chord thickness encodes the similarity score (shared compound count).
How to Read the Plot¶
- Outer Arcs (Samples)
Each colored arc along the circumference corresponds to an individual Sample. -
The length of an arc is typically proportional to the sample's total shared interactions with all other samples (sum of similarity values).
-
Chords (Ribbons)
Each ribbon connecting two arcs represents the similarity between that pair of samples: - a chord exists where the two samples share at least one compound,
-
the placement of chords reveals patterns of connectivity within the sample set.
-
Chord Thickness The thickness of a chord is directly proportional to the number of shared compound co-annotations between the two samples:
- thicker chords indicate high overlap in compound co-annotation profiles,
- thinner chords indicate weaker overlap.
Representative Output¶
The image below illustrates a representative output generated by this use case using the example dataset.
Click on the image to enlarge and explore details.
Interpretation and Key Messages¶
- Annotation-based Sample Groups Groups of samples connected by multiple thick chords may form annotation-based clusters:
- these samples share a similar range of compound co-annotations in the database,
-
they could be worth investigating together for shared annotation patterns.
-
High Similarity Pairs A single very thick chord between two samples may indicate strong pairwise co-annotation overlap:
- these samples have highly overlapping compound co-annotation profiles,
-
they could show annotation redundancy for certain chemical classes.
-
Unique Annotation Profiles A sample with only thin chords (or few connections) to others may possess a more unique compound co-annotation profile:
-
it could be particularly relevant for investigating co-annotations in less common or niche chemical classes.
-
Network-Level Structure The global shape of the chord diagram may reveal:
- densely connected regions corresponding to cores of shared compound co-annotations,
- more peripheral samples with narrower or less overlapping annotation coverage.
Reproducibility and Assumptions¶
-
Input Format
The analysis assumes a semicolon-delimited table containing at least the columnssampleandcompoundname. -
Similarity Definition The similarity metric is explicitly defined as the count of shared unique compound co-annotations between pairs of samples:
- repeated occurrences of the same compound within a sample do not increase the similarity; only uniqueness matters,
-
this provides a direct measure of compound co-annotation overlap.
-
Scope and Limitations
- The chord diagram summarizes overlap in compound co-annotation profiles, not kinetics, expression levels, or pathway completeness.
- It is best interpreted as a structural map of shared compound annotations, to be complemented by more detailed mechanistic analyses in subsequent modules.
Activity diagram of the use case¶
Click on the image to enlarge and explore details.
