UC-5.3 — Regulatory Relevance of Samples¶
Module: 5 – Modeling Interactions of Samples, Genes, and Compounds
Visualization type: Chord diagram (bipartite sample–agency interaction network)
Primary inputs: BioRemPP results table with sample and referenceAG columns
Primary outputs: Interaction matrix of samples × regulatory agencies (co-occurrence counts)
Scientific Question and Rationale¶
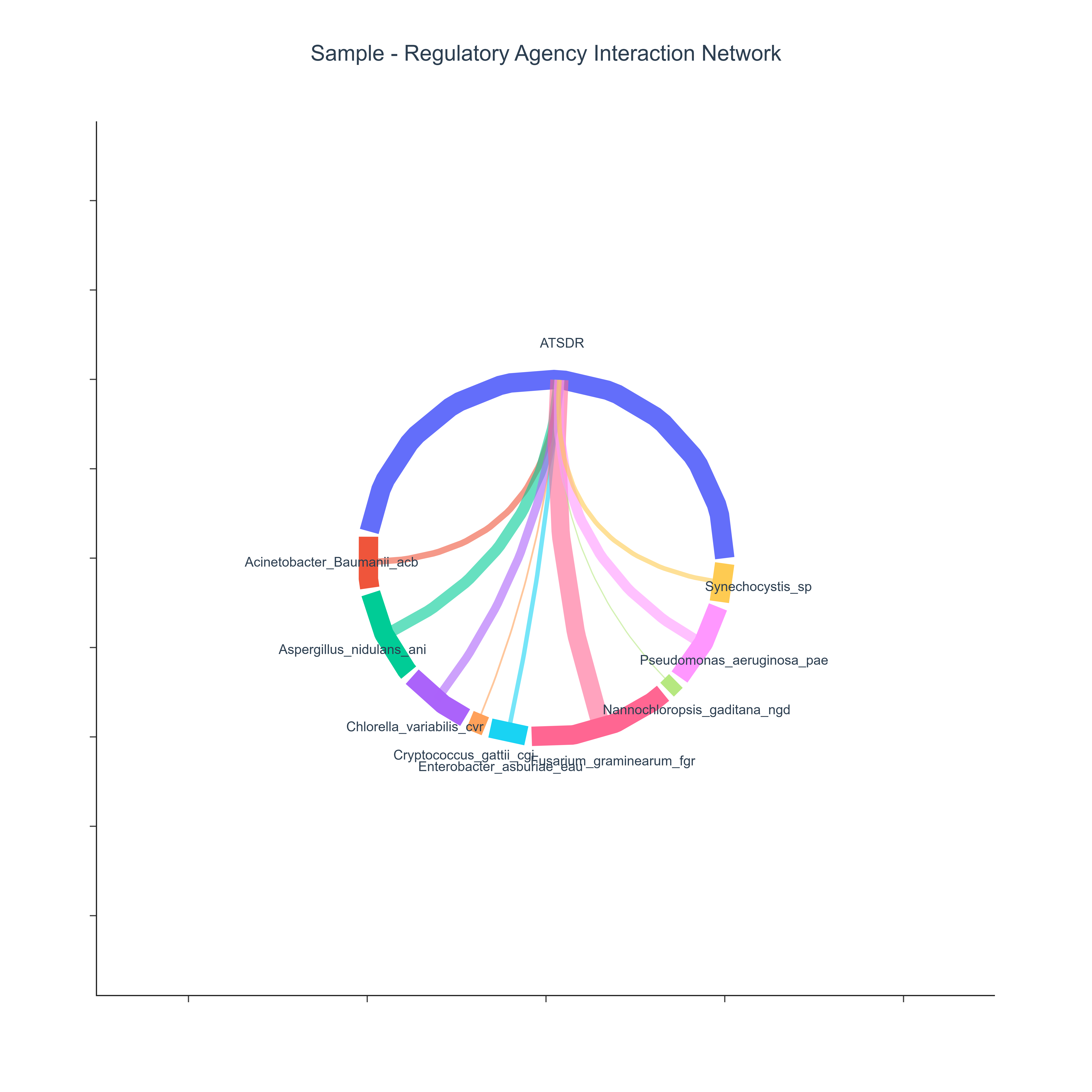
Question: Which samples are most co-annotated with compounds monitored by different environmental regulatory agencies?
This use case quantifies how strongly each biological sample is co-annotated with the regulatory context represented in the dataset. By summarizing co-annotation frequencies between samples and environmental or regulatory agencies (referenceAG), the analysis can reveal which samples are most frequently co-annotated with compounds under formal monitoring. A chord diagram is used to provide an integrated, system-level view of sample–agency co-annotation patterns, which may highlight samples with broad or focused regulatory compound coverage.
Data and Inputs¶
- Primary data source:
BioRemPP_Results.xlsx or BioRemPP_Results.csv - Key columns:
sample– identifier for each biological samplereferenceAG– regulatory or scientific agency label (e.g., WFD, CONAMA, EPC)- Accepted format: semicolon-delimited text table (
.txtor.csv) - Derived structure: interaction matrix with:
- rows = samples
- columns = regulatory agencies
- cell = interaction count for each sample–agency pair
Analytical Workflow¶
-
Data Loading
The primary results table (BioRemPP_Results.xlsx or BioRemPP_Results.csv) is loaded from its semicolon-delimited format. -
Filtering
The dataset is filtered to retain only rows containing valid entries for bothsampleandreferenceAG. Incomplete records are discarded. -
Aggregation (Interaction Strength)
The filtered data is grouped by unique(sample, referenceAG)pairs: - for each pair, the total number of co-occurrence records (rows) is counted,
-
this count provides a measure of interaction strength between the sample and the agency's monitored chemical space.
-
Chord Matrix / Edge List Construction
The aggregated counts are arranged into a matrix or edge list suitable for chord diagram rendering, where: - each sample is treated as one set of nodes,
- each regulatory agency (
referenceAG) is treated as the other set, -
the edge weight between them is the interaction count.
-
Rendering
A chord diagram is generated: - arcs on the circumference represent both samples and regulatory agencies,
- ribbons (chords) connect each sample to the agencies with which it is associated,
- chord thickness encodes interaction strength.
How to Read the Plot¶
- Outer Arcs (Nodes)
Each colored arc along the circle represents either: - a Sample, or
-
a Regulatory Agency (
referenceAG).
The length of an arc is proportional to the total number of interactions (sum of counts) associated with that entity. -
Chords (Ribbons)
The ribbons spanning between arcs represent Sample–Agency relationships: - one end of the ribbon is anchored at a sample arc,
-
the other at an agency arc.
-
Chord Thickness
The thickness of a chord where it connects to an arc is proportional to the interaction strength: - thicker chords may denote stronger associations (more co-occurrences),
- thinner chords reflect weaker or less frequent associations.
Representative Output¶
The image below illustrates a representative output generated by this use case using the example dataset.
Click on the image to enlarge and explore details.
Interpretation and Key Messages¶
- High Co-annotation Frequency with Regulatory Compounds A thick chord between a given sample and a specific agency may indicate high co-annotation frequency of that sample with the agency's monitored compounds:
- the sample is co-annotated with many compounds listed under that agency's purview,
-
suggesting it could be a relevant candidate for further investigation in that regulatory context.
-
Broad vs. Focused Regulatory Coverage
- Samples connected by multiple thick chords to several agencies show broad co-annotation coverage across diverse regulatory frameworks.
-
Samples characterized by one dominant thick chord show more concentrated co-annotation coverage for a specific agency's compound list.
-
Agency-Level Co-annotation Footprint Agencies that receive many substantial chords from different samples may have a broad co-annotation footprint in the dataset:
- their monitored compound lists are widely co-annotated across the available samples,
-
suggesting that many samples carry KO annotations linked to compounds on those lists.
-
Hypothesis Generation for Policy Alignment The chord diagram can help explore alignment between sample annotations and regulatory priorities:
- samples can be compared based on how broadly they cover the compounds of regulatory agencies of interest,
- providing an annotation-level basis for prioritizing experimental follow-up.
Reproducibility and Assumptions¶
-
Input Format
The analysis assumes a semicolon-delimited table containing at least the columnssampleandreferenceAG. -
Interaction Definition
Interaction strength is defined as the total number of co-occurrence records for each(sample, referenceAG)pair in the raw data: - multiple rows linking the same sample and agency (e.g., via different compounds or genes) increase the aggregate count,
-
the chord diagram therefore reflects overall intensity of association, not unique compound or KO counts.
-
Scope and Limitations
- The visualization summarizes co-annotation frequency with regulatory contexts, not compliance status, toxicity levels, or pathway completeness.
- It should be interpreted as a high-level annotation map to prioritize detailed downstream analyses, rather than a standalone compliance assessment.
Activity diagram of the use case¶
Click on the image to enlarge and explore details.
