UC-7.3 — Mapping of Genetic Response to High-Priority Threats¶
Module: 7 – Toxicological Risk Assessment and Profiling
Visualization type: Interactive heatmap (unique gene count per sample–compound pair for high-risk threats)
Primary inputs: BioRemPP_Results.xlsx or BioRemPP_Results.csv (sample–compound–gene associations) and ToxCSM.xlsx or ToxCSM.csv (predicted toxicity per compound and endpoint)
Primary outputs: Matrix of unique gene counts for high-risk compounds across samples, stratified by toxicological super-category
Scientific Question and Rationale¶
Question: For a given high-level toxicological category (e.g., Genomic Toxicity), which samples have the most diverse KO annotations co-annotated with the associated high-priority compounds?
This use case provides an annotation-level view of sample–compound co-annotation patterns for predicted high-risk compounds. By focusing on compounds predicted as "High Toxicity" within a selected toxicological super-category, the heatmap quantifies the KO annotation count each sample has for these priority compounds. The color intensity in each cell reflects the number of unique genes co-annotated with a specific sample–compound pair, which may serve as a measure of annotation breadth for that pairing (experimental validation required to confirm functional capacity).
Data and Inputs¶
- Primary data sources:
BioRemPP_Results.xlsx or BioRemPP_Results.csv– KO annotations linking samples, compounds, and genesToxCSM.xlsx or ToxCSM.csv– predicted toxicity scores and labels for compounds across multiple endpoints- Key columns:
- From
ToxCSM.xlsx or ToxCSM.csv:compoundname– name of the chemical compoundendpoint/label_*– toxicity endpoints and their qualitative labels (e.g., "High Toxicity")supercategory(derived) – toxicological super-category (e.g., Genomic, Environmental, Organic)
- From
BioRemPP_Results.xlsx or BioRemPP_Results.csv:sample– identifier for each biological samplecompoundname– compound associated with the interactiongenesymbol– gene symbol or identifier
- Entities of interest:
- High-Risk Compounds within a chosen toxicological super-category
- Samples and their associated gene co-annotations for these compounds
Analytical Workflow¶
-
User Selection
The user selects a toxicological super-category (e.g., "Genomic", "Environmental", "Organic") from an interactive dropdown menu. -
Threat Scenario Definition (High-Risk Compound Set)
TheToxCSMdataset is filtered to identify allcompoundnameentries that: - belong to the selected super-category, and
-
are labeled "High Toxicity" in at least one endpoint within that category.
The result is a list of high-priority compounds for the chosen threat scenario. -
KO Annotation Count Assessment The
BioRemPP_Results.xlsx or BioRemPP_Results.csvtable is filtered to include only rows in which: -
compoundnameis in the high-priority list obtained in Step 2. This subset captures all sample–gene co-annotation records relevant to the chosen compound class. -
Aggregation and Matrix Construction The filtered data is aggregated to construct a 2D matrix where:
- rows represent high-risk compounds (
compoundname), - columns represent Samples (
sample), and -
each cell value is the count of distinct
genesymbolco-annotated with that sample–compound pair. This count is used as a measure of KO annotation breadth for each sample relative to each high-risk compound. -
Rendering
The sample–compound matrix is rendered as an interactive heatmap: - axis labels denote compounds (rows) and samples (columns),
- color intensity encodes the unique gene count per cell,
- optional hover tooltips expose detailed information (compound, sample, gene count).
How to Read the Plot¶
-
Dropdown Menu
Use the dropdown to select the Toxicological Super-Category of interest (e.g., Genomic, Environmental, Organic). The heatmap updates to reflect high-risk compounds and responses specific to that category. -
Y-axis (Rows)
Represents individual High-Risk Compounds that are predicted as "High Toxicity" within the selected super-category. -
X-axis (Columns) Represents individual Samples, each with co-annotation records for one or more of the high-risk compounds.
-
Cell Color The color intensity of each cell indicates the count of unique genes (
genesymbol) co-annotated with a specific sample–compound pair: - more intense (warmer, darker) colors correspond to higher gene counts,
- lighter colors correspond to fewer co-annotated genes or no detected association.
Representative Output¶
The image below illustrates a representative output generated by this use case using the example dataset.
Click on the image to enlarge and explore details.
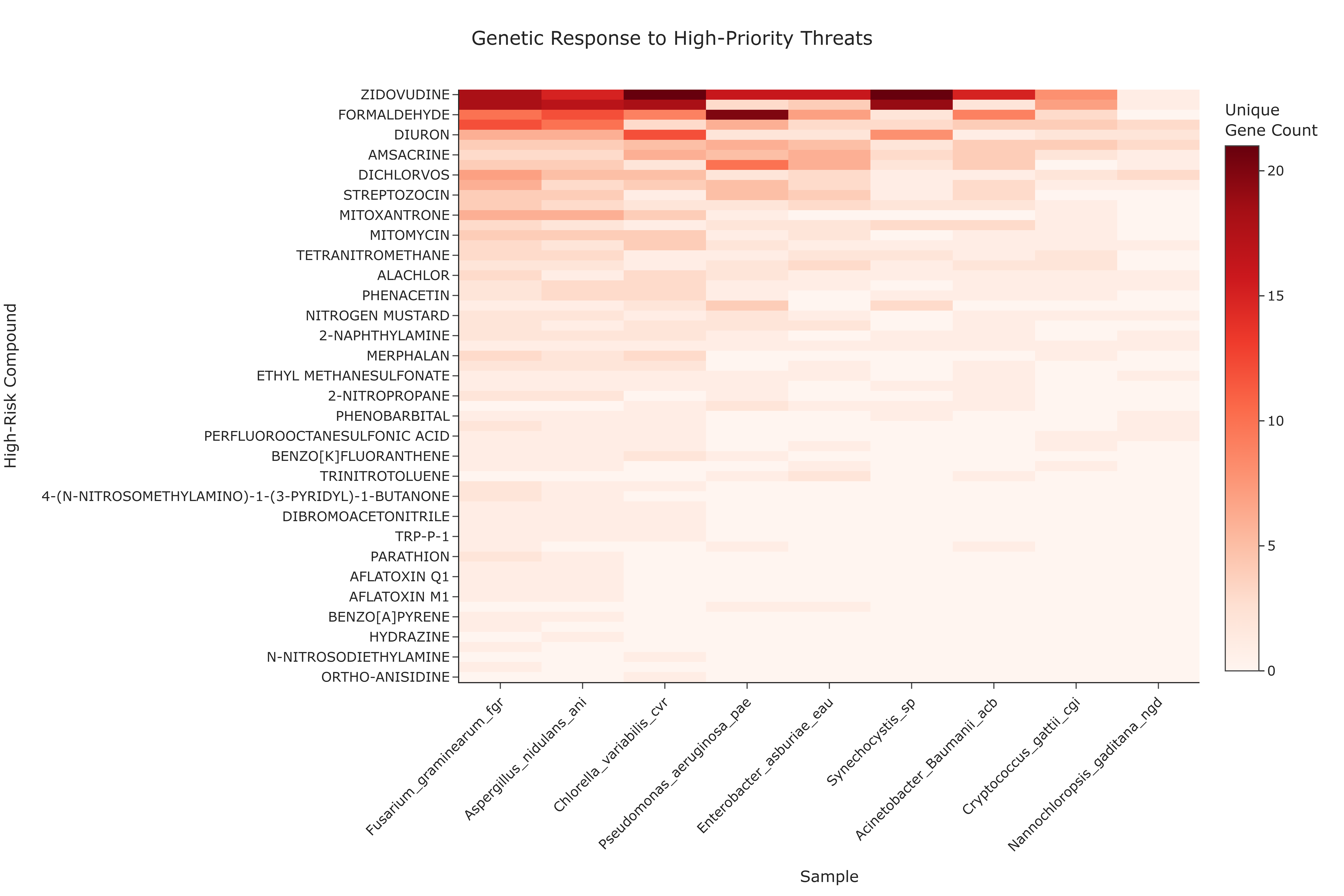
Interpretation and Key Messages¶
- Samples with High KO Annotation Counts Brightly colored cells ("hotspots") may highlight sample–compound pairs with broad co-annotation coverage, where a sample has many KO annotations co-annotated with a specific high-risk compound.
-
A column with many bright cells may indicate a sample with high KO annotation coverage across the selected toxicological category (experimental validation required to confirm functional capacity).
-
Widely Co-annotated Priority Compounds A row with many bright cells may signify a high-risk compound that is co-annotated with many genes across multiple samples. Such compounds could be:
- broadly annotated targets warranting prioritized experimental investigation, or
-
candidates for cross-sample annotation comparison.
-
Annotation-based Sample Comparison for Hypothesis Generation By examining both rows and columns, users can compare KO annotation profiles across samples relative to a specific toxicological domain. For example:
-
when "Genomic" is selected, samples with the broadest annotation coverage can be identified as candidates for further investigation (experimental validation required to confirm mitigation capacity).
-
Annotation Overlap vs. Annotation Complementarity Overlapping bright cells across multiple samples for the same compound may indicate high annotation redundancy, while complementary patterns (different samples covering different compounds) could suggest distinct annotation profiles across samples.
Reproducibility and Assumptions¶
- Input Format
The analysis requires two semicolon-delimited tables: ToxCSM.xlsx or ToxCSM.csv– containing compound-level toxicity predictions and labels,-
BioRemPP_Results.xlsx or BioRemPP_Results.csv– containing sample–compound–gene associations. -
Definition of "High Toxicity"
A compound is considered high-risk within a super-category if it is labeled "High Toxicity" for at least one endpoint mapped to that category. -
KO Annotation Count Metric The annotation count is quantified as the count of unique gene symbols co-annotated per sample–compound pair. This is treated as a measure of:
- annotation breadth, and
-
the diversity of KO annotations associated with that sample–compound context (not a direct measure of degradation or mitigation capacity).
-
Model and Annotation Limitations
The analysis reflects: - the predictive scope and calibration of ToxCSM, and
- the coverage and curation of BioRemPP annotations.
It does not directly incorporate expression levels, kinetic parameters, or environmental exposure, which may require additional data and analyses.
Activity diagram of the use case¶
Click on the image to enlarge and explore details.
