UC-8.1 — Minimal Sample Grouping for Complete Compound Coverage¶
Module: 8 – Assembly of Functional Consortia
Visualization type: Interactive faceted scatter plot (minimal non-redundant functional guilds)
Primary inputs: BioRemPP_Results.xlsx or BioRemPP_Results.csv (sample–compound associations)
Primary outputs: Minimal set of "functional guilds" providing complete compound coverage within a selected chemical class
Scientific Question and Rationale¶
Question: What is the minimum number of distinct compound co-annotation profiles (i.e., groups of samples with identical compound co-annotation sets) required to collectively cover all observed compound co-annotations within a given chemical class?
This use case formalizes candidate consortium selection as a set cover problem at the annotation level. By clustering samples into annotation groups that share identical compound co-annotation sets within a specific chemical class, and then selecting the smallest subset of these groups that collectively cover all compounds, the analysis may reveal the minimal, non-redundant candidate set needed to achieve full compound annotation coverage. This can provide a principled, annotation-based foundation for hypothesis-driven consortium design (experimental validation is required to confirm functional capacity).
Data and Inputs¶
- Primary data source:
BioRemPP_Results.xlsx or BioRemPP_Results.csv(semicolon-delimited) - Key columns:
sample– identifier for each biological samplecompoundclass– chemical class to which a compound belongs-
compoundname– name of the chemical compound interacted with by the sample -
Core concept: Annotation Groups An annotation group is defined as a group of samples that share the exact same set of compound co-annotations within a selected chemical class. Samples within the same group have identical annotation profiles with respect to that class.
Analytical Workflow¶
-
User Selection (Chemical Class)
The user selects acompoundclassfrom an interactive dropdown menu (e.g., Aromatics, Chlorinated, Metals). This choice defines the chemical space to be analyzed. -
Dynamic Filtering
The primary results table (BioRemPP_Results.xlsx or BioRemPP_Results.csv) is filtered to retain only rows where: compoundclassequals the selected class, and- both
sampleandcompoundnameare valid and non-missing.
This subset represents all observed compound co-annotations for samples within the chosen class.
- Sample Grouping into Annotation Groups For each
sample, the set of associatedcompoundnamevalues (within the selected class) is computed. - Samples whose compound co-annotation sets are identical are grouped into the same annotation group.
-
Each group is thus characterized by a unique compound annotation profile and a list of member samples.
-
Minimization via Set Cover (Greedy Heuristic) A greedy set cover algorithm is applied to the annotation groups:
- Initialize the set of uncovered compounds as all unique
compoundnamevalues in the selected class. - Iteratively select the group that covers the largest number of currently uncovered compounds.
- Remove these compounds from the uncovered set and repeat until all compounds are covered.
The result is a minimal (or near-minimal) subset of annotation groups that collectively cover every compound co-annotation in the selected class.
- Rendering
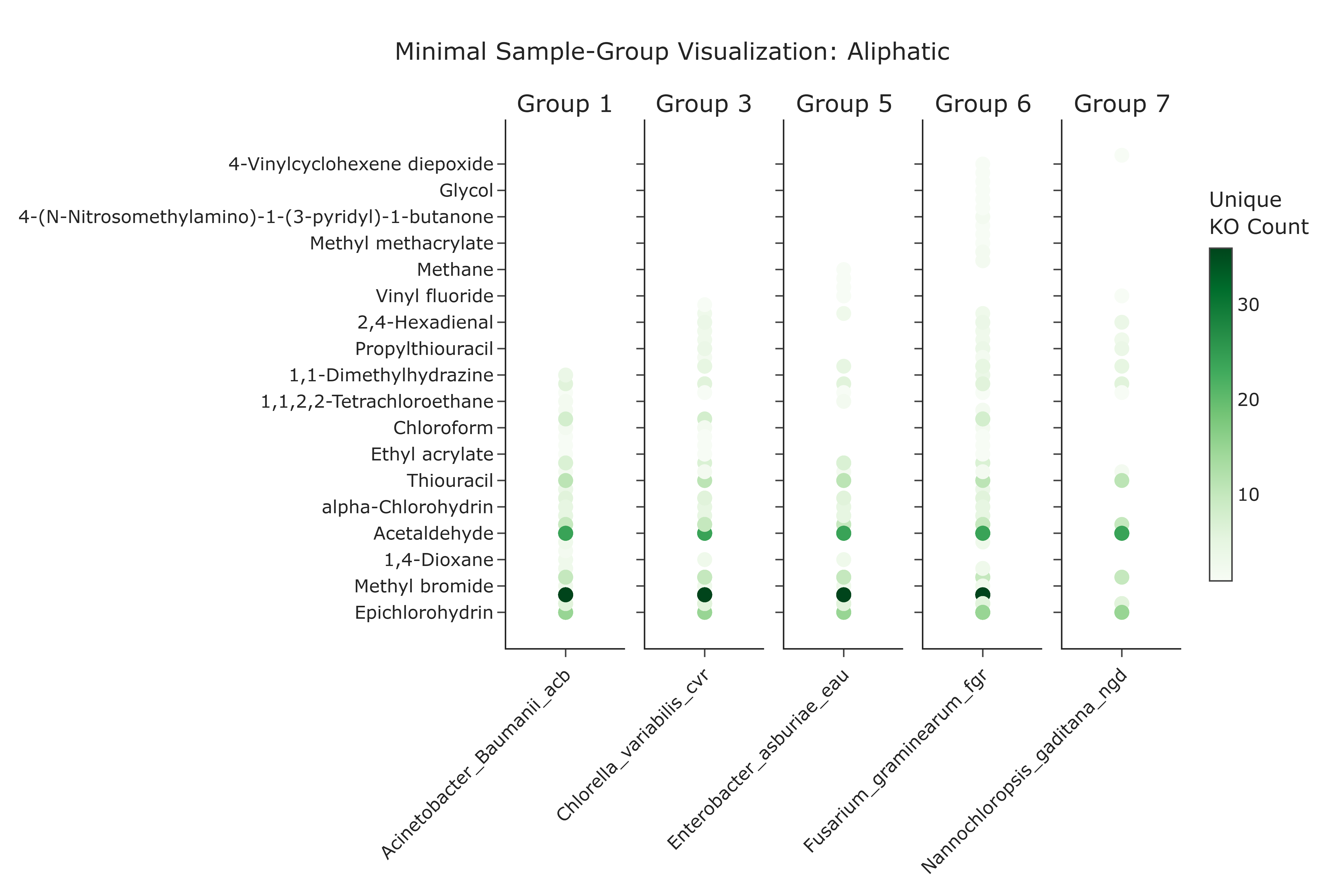
The minimal guild set is visualized as a faceted scatter plot: - each facet (subplot) corresponds to one selected functional guild,
- within a facet, the x-axis lists member
samples and the y-axis listscompoundnames, - points mark the presence of a sample–compound interaction, visually confirming the guild's profile.
How to Read the Plot¶
-
Dropdown Menu
Use the dropdown to choose the Compound Class. The full pipeline (filtering, guild detection, set cover, and plotting) is recomputed and the visualization is updated accordingly. -
Subplots (Facets) Each subplot represents one minimal required annotation group:
- the number of subplots equals the number of annotation groups selected by the set cover algorithm,
-
each subplot represents a distinct compound co-annotation profile covering a subset of the selected class.
-
Y-axis (Compounds)
Lists the Compound Names that define the chemical profile of that guild within the selected class. -
X-axis (Samples)
Lists the Samples that belong to that guild.
All samples within a subplot share the same compound interaction profile. -
Points (Co-annotations) A point at the intersection of a sample and a compound indicates an observed co-annotation (i.e., the sample has at least one KO annotation linking it to that compound).
Representative Output¶
The image below illustrates a representative output generated by this use case using the example dataset.
Click on the image to enlarge and explore details.
Interpretation and Key Messages¶
- Annotation Redundancy The number of subplots (minimal annotation groups) can provide an immediate measure of annotation redundancy:
- Few groups → high redundancy: many samples share similar compound co-annotation profiles.
-
Many groups → low redundancy: compound annotation coverage relies on multiple distinct annotation profiles.
-
Core vs. Niche Annotation Profiles
- A group whose subplot contains many samples may represent a widely distributed co-annotation profile common across samples; these could be robust, broadly shared annotation patterns.
-
A group with only one or two samples may represent a niche annotation profile, potentially encoding co-annotations that cannot be easily replaced.
-
Annotation-guided Minimal Candidate Set This analysis can be valuable for identifying minimal candidate consortia at the annotation level:
- by selecting one representative sample per annotation group from the minimal set, one could achieve complete compound annotation coverage for the chosen class,
-
this may minimize annotation overlap while preserving full coverage, useful for hypothesis generation (experimental validation required to confirm functional capacity).
-
Trade-offs and Extensions Although the minimal set emphasizes parsimony, additional samples from the same annotation groups can be added to increase annotation redundancy (e.g., as a proxy for potential robustness against variability or loss of specific members).
Reproducibility and Assumptions¶
- Input Format
The analysis assumes a semicolon-delimitedBioRemPP_Results.xlsx or BioRemPP_Results.csvtable containing at least: sample,compoundclass,-
compoundname. -
Definition of Annotation Groups Annotation groups are defined strictly by identical compound co-annotation sets within the selected class. Even a single additional or missing compound differentiates two groups.
-
Set Cover Approximation
The minimization step uses a greedy heuristic for the set cover problem: - this approach is computationally efficient and typically near-optimal,
-
however, it does not guarantee the absolute mathematically minimal number of guilds in all possible cases.
-
Annotation Interpretation The analysis is based on observed sample–compound co-annotations. It does not encode kinetic parameters, environmental abundance, or interaction strength; it answers a structural annotation question: Which distinct co-annotation profiles are minimally required to cover all compound co-annotations in a given class?
Activity diagram of the use case¶
Click on the image to enlarge and explore details.