UC-8.5 — KEGG Pathways Completeness Scorecard¶
Module: 8 – Assembly of Functional Consortia
Visualization type: Interactive heatmap (Pathway Completeness Score per sample–pathway pair)
Primary inputs: KEGG_Results.xlsx or KEGG_Results.csv (sample–KO–KEGG pathway associations)
Primary outputs: Matrix of per-sample Pathway Completeness Scores for KEGG metabolic pathways
Scientific Question and Rationale¶
Question: Which samples have the most "complete" KO annotation coverage for a given KEGG metabolic pathway, and how can this be used to compare KO annotation completeness across samples?
This use case extends the completeness framework to the KEGG metabolic pathway space. For each KEGG pathway, the analysis quantifies what fraction of its KEGG Orthology (KO) identifiers (as observed in the dataset) are present in a given sample. The resulting Pathway Completeness Score (in %) may allow identification of samples with high KO annotation completeness, characterization of samples with broad KO coverage across pathways, and detection of pathways with distributed KO coverage across samples (experimental validation required to confirm functional capacity).
Data and Inputs¶
- Primary data source:
KEGG_Results.xlsx or KEGG_Results.csv(semicolon-delimited) - Key columns:
sample– identifier for each biological sampleko– KEGG Orthology (KO) identifier-
pathname– KEGG pathway name or identifier associated with the KO -
Scorecard structure:
- Rows: Samples
- Columns: KEGG Pathways (
pathname) - Cell value: Pathway Completeness Score (%) for each
(sample, pathname)pair
Analytical Workflow¶
-
Data Loading
The KEGG analysis results tableKEGG_Results.xlsx or KEGG_Results.csvis loaded from its semicolon-delimited format. -
Feature Engineering – Pathway Completeness Score
For each KEGG pathway, the following three-step calculation is performed: -
KO Universe per Pathway
For eachpathname, determine the universe of unique KOs observed for that pathway across all samples. -
Sample-Specific KO Count
For each(sample, pathname)pair, count the number of unique KOs that the sample possesses for that pathway. -
Score Calculation
Compute the Pathway Completeness Score (%) as:
Pathway Completeness Score = (unique KOs in sample for that pathway / total unique KOs for that pathway) × 100. -
Matrix Construction
The per-pair scores are reshaped into a 2D matrix: - rows represent
sample, - columns represent
pathname, -
cell values store the Pathway Completeness Score (%).
-
Rendering as Heatmap
The matrix is rendered as an interactive heatmap: - cell color intensity is proportional to the Pathway Completeness Score,
- optional numeric labels inside cells can display the exact percentage.
How to Read the Plot¶
-
Y-axis (Rows)
Each row corresponds to a single Sample. -
X-axis (Columns)
Each column corresponds to a KEGG Pathway (pathname). -
Cells (Color and Label)
- The color intensity of each cell encodes the Pathway Completeness Score (%) for that sample–pathway pair.
- Brighter or warmer colors indicate higher completeness, while darker or cooler colors indicate lower completeness.
- If enabled, numeric labels provide the exact percentage value.
Representative Output¶
The image below illustrates a representative output generated by this use case using the example dataset.
Click on the image to enlarge and explore details.
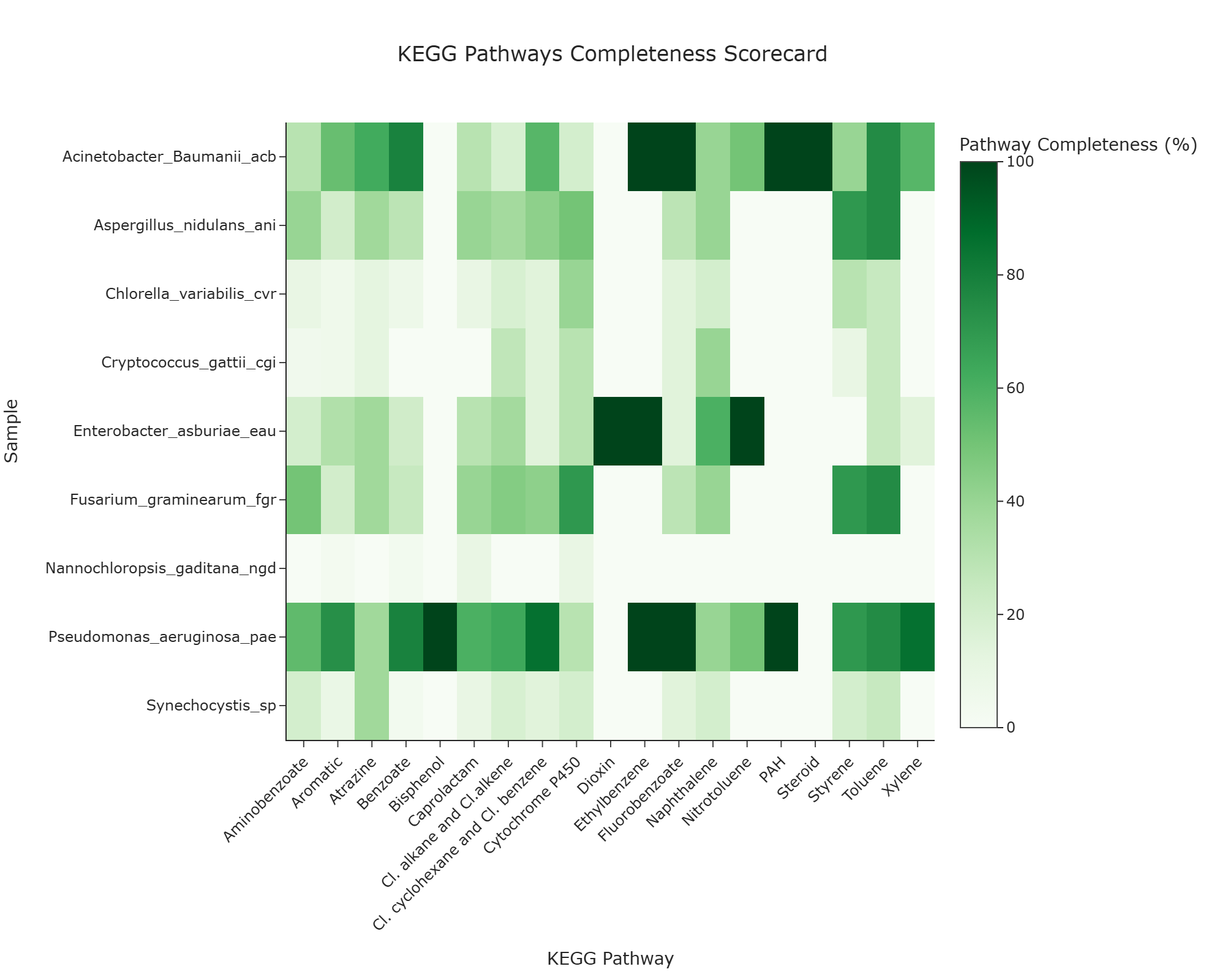
Interpretation and Key Messages¶
- Samples with High KEGG Pathway KO Completeness Brightly colored cells ("hotspots") may indicate samples with high KO annotation completeness for specific KEGG pathways:
- a 100% score means the sample has all KOs observed for that pathway in the dataset,
-
such samples could be annotation-level candidates for prioritized experimental investigation where that pathway is relevant.
-
Assessing Breadth of KO Pathway Coverage Reading across a row (left to right) may reveal the KO annotation breadth of a sample across KEGG pathways:
- multiple high-scoring cells may indicate a sample with broad KO annotation coverage across many different pathways,
-
one or a few high-scoring cells may indicate a sample with narrower, pathway-focused KO annotation coverage.
-
Distributed Pathway KO Coverage Reading down a column (top to bottom) may reveal how distributed a pathway's KO coverage is across samples:
- if no sample reaches a high completeness score, the pathway has distributed KO coverage across samples,
-
these pathways may be candidates for multi-sample KO annotation complementarity analyses (experimental validation required to confirm functional coverage).
-
Integrating KEGG with Other Annotation Layers This KEGG-based completeness view can complement:
- HADEG pathway completeness (UC-8.4), and
- compound and class-level completeness metrics (UC-8.2, UC-8.3), enabling multi-layered annotation-based reasoning about which samples and combinations have the highest KO annotation coverage for further experimental investigation.
Reproducibility and Assumptions¶
- Input Format
The analysis requires a semicolon-delimited KEGG results table containing at least: sample,ko,-
pathname. -
Definition of KO Universe per Pathway
For each KEGG pathway, the "total universe" of KOs is defined by the dataset: - it includes all unique KOs observed for that pathway across all samples in
KEGG_Results.xlsx or KEGG_Results.csv, -
no external canonical KEGG pathway definition is enforced in this calculation.
-
Normalization
The Pathway Completeness Score is expressed as a percentage, allowing fair comparison: - between pathways with different total KO counts, and
-
between samples with varying annotation depths.
-
Interpretation Scope As with other completeness metrics in Module 8, the KEGG Pathway Completeness Score reflects KO annotation presence, not kinetic rates, gene expression levels, confirmed functional capacity, or regulatory control. It should be interpreted as a KO annotation coverage indicator, to be integrated with other BioRemPP analyses when generating hypotheses for candidate consortium assembly.
Activity diagram of the use case¶
Click on the image to enlarge and explore details.